Of BuzzFeed’s 76.7 million multiplatform unique visitors in April (comScore), 17 percent were coming for news. The publisher historically hasn’t broken out its content by vertical to comScore, like other top news sites including CNN, Yahoo and The Huffington Post do. But it started to on a limited basis as of last month, when it began breaking out its Entertainment and Life coverage (43.7 million and 20.1 million uniques, respectively) to comScore. Stripping out those verticals leaves 13 million uniques for the rest, including hard news.
Ignoring analysis for the moment, let’s just look at the reasoning here. Unique browsers can visit more than one section of a site, so it’s possible that there’s overlap, and that simply subtracting the known verticals from the known total traffic isn’t a useful way to start. (I’m not certain of comScore’s methodology for vertical breakouts, but would be surprised if it doesn’t let sites count a user twice in different verticals, given that audiences overlap.)
So that 17% could be higher than it appears at first. Then, that 17% includes hard news plus everything that doesn’t fit into Entertainment or Life, so the actual audience for Buzzfeed’s news could be smaller than it appears at first.
The other element here is that unique browsers are the broadest possible metric, and likely to show news in the brightest light. In March, again according to comScore, Buzzfeed averaged 4.9 visits per visitor and 2 views per visit in the US, for roughly 10 views per visitor. If, among the 17% who visited news at all, five of those views are to news, then news is very, very well read with an exceptionally loyal audience. If just one of those views is to news, then news is much less well read than “17% of traffic” might suggest.
This post has been brought to you by early morning web analytics pedantry.
Update: Digiday has now altered the headline of its post and the text of the paragraph posted above.
I’ve been thinking about this Tow study for a while now. It looks at how stats are used in the New York Times, Gawker and Chartbeat; in the case of the latter, it examines how the company builds its real-time product, and for the former, how that product feeds in (or fails to feed in) to a newsroom culture around analytics. There’s lots to mull over if part of your work, like mine, includes communication and cultural work about numbers. The most interesting parts are all about feelings.
Petre says:
Metrics inspire a range of strong feelings in journalists, such as excitement, anxiety, self-doubt, triumph, competition, and demoralization. When devising internal policies for the use of metrics, newsroom managers should consider the potential effects of traffic data not only on editorial content, but also on editorial workers.
Which seems obvious, but probably isn’t. Any good manager has to think about the effects of making some performance data – the quantifiable stuff – public and easily accessible, on a minute-by-minute basis. The fears about numbers in newsrooms aren’t all about the data coming to affect decisions – the “race to the bottom”-style rhetoric that used to be very common as a knee-jerk reaction against audience data. Some of the fears are about how analytics will be used, and whether it will drive editorial decision-making in unhelpful ways, for sure, but the majority of newsroom fear these days seems to be far simpler and more personal. If I write an incredible, important story and only a few people read it, is it worth writing?
Even Buzzfeed, who seem to have their metrics and their purpose mostly aligned, seem to be having issues with this. Dao Nguyen has spoken publicly about their need to measure impact in terms of real-life effects, and how big news is by those standards. The idea of quantifying the usefulness of a piece of news, or its capacity to engender real change, is seductive but tricky: how do you build a scale between leaving one person better informed about the world to, say, changing the world’s approach to international surveillance? How do you measure a person losing their job, a change in the voting intention of a small proportion of readers, a decision to make an arrest? For all functional purposes it’s impossible.
But it matters. For the longest time, journalism has been measured by its impact as much as its ability to sell papers. Journalists have measured themselves by the waves they make within the communities upon which they report. So qualitative statements are important to take into account alongside quantitative measurements.
The numbers we report are expressions of value systems. Petre’s report warns newsrooms against unquestioningly accepting the values of an analytics company when picking a vendor – the affordances of a dashboard like Chartbeat can have a huge impact on the emotional attitude towards the metrics used. Something as simple as how many users a tool can have affects how something is perceived. Something as complex as which numbers are reported to whom and how has a similarly complex effect on culture. Fearing the numbers isn’t the answer; understanding that journalists are humans and react in human ways to metrics and measurement can help a great deal. Making the numbers actionable – giving everyone ways to affect things, and helping them understand how they can use them – helps even more.
Part of the solution – there are only partial solutions – to the problem of reach vs impact is to consider the two together, but to look at the types of audiences each piece of work is reading. If only 500 people read a review of a small art show, but 400 of those either have visited the show or are using that review to make decisions about what to see, that piece of work is absolutely valuable to its audience. If a story about violent California surfing subcultures reaches 20,000 people, mostly young people on the west coast of the US, then it is reaching an audience who are more likely to have a personal stake in its content than, say, older men in Austria might.
Shortly after I arrived in New York I was on a panel which discussed the problems of reach as a metric. One person claimed cheerfully that reach was a vanity metric, to some agreement. A few minutes later we were discussing how important it was to reach snake people (sorry, millennials) – and to measure that reach.
Reach is only a vanity metric if you fail to segment it. Thinking about which audiences need your work and measuring whether it’s reaching them – that’s useful. And much less frightening for journalists, too.
From Nieman Lab, an interesting look at how the NYT maps traffic between stories, and analyses why and how things are providing onward traffic or causing people to click away from the site.
One example has been in our coverage of big news events, which we tend to blanket with all of the tools at our disposal: articles (both newsy and analytical) as well as a flurry of liveblogs, slideshows, interactive features, and video. But we can’t assume that readers will actually consume everything we produce. In fact, when we looked at how many readers actually visited more than a single page of related content during breaking news the numbers were much lower than we’d anticipated. Most visitors read only one thing.
This tool’s been used to make some decisions and change stories, individually, to improve performance in real time. That’s the acid test of tools like this – do they actually get used?
But the team that uses it is the data team, not the editorial team – yet. Getting editors to use it regularly is, it seems, about changing these data-heavy visualisations into something editors are already used to seeing as part of their workflow:
we’re thinking about better ways to automatically communicate these insights and recommendations in contexts that editors are already familiar with, such as email alerts, instant messenger chat bots, or perhaps something built directly into our CMS.
It’s not just about finding the data. It’s also about finding ways to use it and getting it to the people best placed to do so in forms that they actually find useful.
One of the interesting sidelines to come out of the remarkably interesting leaked NYT innovation report in the last few days has been the fact that traffic to the NYT homepage has halved in two years. It’s an intriguing statistic, and more than one media outlet has taken it and run with it to create a beguiling narrative about how the homepage is dead, or at the very least dying, why, and what this means for news organisations.
But what’s true for the NYT is certainly not true for the whole of the rest of the industry. Other pages – articles and tag pages – are certainly becoming more important for news organisations, but that doesn’t mean the homepage no longer matters – or that losing traffic to it is a normal and accepted shift in this new digital age. Losing traffic proportionately makes sense, but real-terms traffic loss looks rather unusual.
Audience stats like this are usually closely guarded secrets, because of their commercial sensitivity, but it’s fair to suggest that homepage traffic (at least, to traditionally organised news homepages) is a reasonable indicator of brand loyalty, of interest in what that organisation has to say, and of trust that organisation can provide an interesting take on the day. Bookmarking the homepage or setting it as a start point for an internet journey is an even bigger mark of faith, a suggestion that one site will tell you what’s most important at any given moment when you log in – but it’s very hard even for sites themselves to measure bookmark stats, never mind to get some sort of broad competitor data that would shed light on whether that behaviour is declining.
It’s plausible, therefore, that brand search would be a rough indicator of brand loyalty and therefore of homepage interest; the New York Times is declining there, while the Daily Mail, for example, has been rocketing to new highs recently. I would be incredibly surprised if the Mail shares this pessimism about the health of the homepage, based on its own numbers. (That’s harder to measure for The Atlantic, whose marine namesake muddies the search comparison somewhat.)
The death of the homepage, much like the practice of SEO and pageviews as a metric, has been greatly exaggerated. What’s happening here, as Martin Belam points out, is more complicated than that. As the internet is ageing, the older, standard ways of doing business and distributing content are changing, and are being joined by newer models and methods. Joined, not supplanted, unless of course you’ve created your new shiny thing purely to focus on the new stuff rather than the old stuff, the way Buzzfeed focuses on social and Quartz doesn’t have any real homepage at all.
You need to be thinking about SEO and social, pageviews and engagement metrics, the homepage and the article page. Older techniques don’t die just because we’ve all spotted something newer and sexier, unless the older thing stopped serving a genuine need; the resurgence of email is proof enough of that. Diversify your approach. Beware of zombies.
Jason Kint, in an interesting piece at Digiday, argues that page views are rubbish and we should use time-based metrics to measure online consumption.
Pageviews and clicks fuel everything that is wrong with a clicks-driven Web and advertising ecosystem. These metrics are perfectly suited to measure performance and direct-response-style conversion, but tactics to maximize them inversely correlate to great experiences and branding. If the goal is to measure true consumption of content, then the best measurement is represented by time. It’s hard to fake time as it requires consumer attention.
Some issues here. Time does not require attention: I can have several browser tabs open and also be making a cup of tea elsewhere. TV metrics have been plagued by the assumption that TV on === attentively watching, and it’s interesting to see that fallacy repeated on the web, where a branching pathway is as easy as ctrl+click to open in a new tab. It’s also easy to game time on site by simply forcing every external link to open in a new tab: it’s awful UX, but if the market moves to time as the primary measurement in the way that ad impressions are currently used, I guarantee you that will be widely used to game it, along with other tricks like design gimmicks at bailout points and autorefresh to extend the measured visit as long as possible. Time is just as game-able as a click.
It’s worth noting that Kint is invested in selling this vision of time-based metrics to the market. That doesn’t invalidate what he says out of hand, of course, but it is important to remember that if someone is trying to sell you a hammer they are unlikely to admit that you might also need a screwdriver.
In a conversation on Twitter yesterday Dave Wylie pointed me to a Breaking News post which discusses another time-based metric – time saved. It’s a recognition that most news consumers don’t actually want to spend half an hour clicking around your site: they want the piece of information they came for, and then they want to get on with their lives. Like Google, which used to focus on getting people through the site as fast as possible to what they needed. Or like the inverted pyramid of news writing, which focusses on giving you all the information you need at the very top of the piece, so if you decide you don’t need all the details you can leave fully informed.
There’s a truism in newsroom analytics: the more newsy a day is, the more traffic you get from Google News or other breaking news sources, the less likely those readers are to click around. That doesn’t necessarily mean you’re failing those readers or that they’re leaving unsatisfied; it may in fact make them more likely to return later, if the Breaking News theory holds true for other newsrooms. Sometimes the best way to serve readers is by giving them less.
“I think of competing for users’ attention as a zero-sum game. Thanks to hardware innovation, there is barely a moment left in the waking day that hasn’t been claimed by (in no particular order) books, social networks, TV, and games. It’s amazing that we have time for our jobs and families.
“There’s no shortage of hand-wringing around what exactly “engagement” means and how it might be measured?—?if it can be at all.Of course, it depends on the platform, and how you expect your users to spend their time on it.
“For content websites (e.g., the New York Times), you want people to read. And then come back, to read more.
“A matchmaking service (e.g., OkCupid) attempts to match partners. The number of successful matches should give you a pretty good sense of the health of the business.
“What about a site that combines both of these ideas? I sometimes characterize Medium as content matchmaking: we want people to write, and others to read, great posts. It’s two-sided: one can’t exist without the other. What is the core activity that connects the two sides? It’s reading. Readers don’t just view a page, or click an ad. They read.
“At Medium, we optimize for the time that people spend reading.
Medium, as a magazine-style publisher(/platform/hybrid thing), wants a browsing experience in which every article is fully read through and digested, and where the next piece follows on from the former serendipitously. News publishers don’t necessarily want that, or at least not across the board. For features the approach makes a lot of sense, but for news that’s geared towards getting the important facts across in the first paragraphs – even the first sentence – it’s fundamentally at odds with the writer’s goals. News that aims to be easy to read shouldn’t, and doesn’t, take a lot of time to consume. So generalist publishers have to balance metrics for success that are often in direct conflict. (This is one of many reasons why, actually, page views are pretty useful, with all the necessary caveats about not using stupid tricks to inflate things and then calling it success, of course.)
Newsrooms also have to use – buzzwordy as the phrase is – actionable metrics. It doesn’t matter what your numbers say if no one can use them to make better decisions. And newsrooms have something that Medium doesn’t: control over content. Medium doesn’t (for the most part) get to dictate what writers write, how it’s structured, the links it contains or the next piece that ought to follow on from it. So the questions it wants to answer with its metrics are different from those of editors in most newsrooms. Total time reading is most useful for news publishers in the hands of devs and designers, those who can change the furniture around the words in order to improve the reading experience and alter the structure of the site to improve stickiness and flow. Those are rarely editorial decisions.
The clue’s in the headline – it’s Medium’s metric that matters. Not necessarily anyone else’s.
Newsrooms still tend to be weird about data. Not external data, that comes from governments or companies as part of a news story – we’re getting much better at that. But internal data, the numbers we generate ourselves. Web stats tend to be left to teams who use them mostly for commercial stuff. They exist as Big Numbers that newsrooms want to increase but don’t really understand why or how to do so. Editorial people who want to know their data tend to be given the numbers that are useful for commercial or sales teams, because those are the ones that matter to the business’s bottom line; they don’t tend to get much training in how to dig into the numbers themselves, or in analysing and applying that data to their own domain. Which is, to be honest, a bit of a shame. Stijn Debrouwere recently wrote an excellent talk about cargo cult analytics – about the problem of newsrooms assembling data packages that look great, but that don’t bring anyone any closer to actually acting on the data in useful ways. The most frustrating thing about this situation is that most newsrooms are stuffed with people who spend all day approaching things with curiosity, interest and an eye towards discovering something of use. Newsrooms today tend to include data journalists, people with at least a basic stats background, people who know the internet incredibly well, people who are excellent at sifting information and then distilling it down to the bits that matter. But those skills aren’t always applied to the data news organisations themselves produce. So this is a basic guide for journalists who want to get started on web stats – not for the technical skills you need, but the sorts of questions to ask, ways to approach the problems involved.
Which numbers matter?
This is probably the most important question, and one most companies have a very hard time answering. It’s always tempting simply to look at the top line – the biggest collection of data you can find – perhaps split by referrer or by section if you’re working on a large site. But the top line isn’t generally very helpful, unless you know what it’s made from and how much of it is actually useful traffic. The definition of ‘useful’ varies depending on what you’re trying to do – useful for an editor and useful for an advertiser are not the same thing. Useful in live stats and useful in long term analysis are not the same. The numbers that matter aren’t going to be the biggest ones you can find, unsegmented page views or monthly unique users. Those hide a multitude of smaller and much more interesting numbers. Numbers with a financial value attached; numbers that are too small, or too big, or unbalanced in some way. Numbers that are interesting in part because they’re not what you want them to be. Numbers you can work to change. Those are the interesting ones. Commissioning editor? Try Stijn’s monthly active users to daily active users ratio. Front page editor? Try loyal bounces – people who hit your front page for a second or third time in a day but only view one page before leaving. Journalist? Try daily referrals from your Twitter account. There are dozens of interesting numbers, when you start looking. Try non-registered users who view more than three pages per visit. Try email traffic. Try people who didn’t come back last month. (That one will almost certainly upset you.)
What’s normal?
You won’t know whether you’re seeing something new or unusual until you understand what normal is. What does an average day look like? What shapes and patterns would you expect to see in the data? Is it normal to have 25% of your users on mobile, or 10% from Belgium, or are those surprisingly high or low? And what about other comparable sites – is your data broadly similar to your peers or are there unexpected elements that make you special?
Why’s normal?
This is a bit more difficult to work out, but it’s worth trying to understand. Why is the status quo the way it is? Why do you see spikes in traffic at 9am, midday, and midnight on weekdays? Why do you get most of your traffic from Google, or Facebook, or a suite of obscure cycling forums? This is your current audience: understanding why it operates the way it does, the context and the wider web in which your data fits, will help you understand which levers you can pull to change it.
What questions can I ask?
Just being in possession of a bunch of numbers isn’t that interesting. What matters is how you can use them. This is pre-interview prep work, and a basic data journalism skill. Which questions can you ask that are going to get you a story? How and why are more interesting than what and when, on the whole, but also much harder to answer. Knowing that something’s unusual, or knowing a trend exists, is less interesting than understanding why that is, whether it’s a good or bad thing, and how it might be changed.
What’s the context?
Contextualising data helps you understand it, and identify potentially-useful patterns. Seeing weird Google-related activity around a particular piece on a celebrity at certain times of day or week? Check the TV guide. I remember once discovering that a four-year-old article about young entrepreneurs was getting unexpected fresh traffic because it ranked well for the name of a man who featured in a Google Chrome TV ad – in which he Googles his own name. Every time the ad aired, we had spikes of people copying him and clicking through. That’s a great opportunity to make sure that piece has good related links, and acts as a decent first page for someone hitting the site. Think about seasonality, and geography. Seasonal traffic changes can be vital context, and so can the fact that seasons aren’t the same all over the world. Behaviour online isn’t divorced from behaviour offline, and TV in particular influences it far more than might be obvious (see also: Miley Cyrus). Knowing the context for a number helps you identify causes and work out whether something is a fluke, something you can influence, or something you can take advantage of.
Grind fine and experiment
Seeing behaviour on your site in real time is genuinely useful – if you have a newsroom setup that lets you react to it. There’s no point having a dataset that you can’t, or won’t, use. Watching a big number on a graph climb is great for morale, and watching it sink is hard work; but neither requires much response in most newsrooms aside from checking your watch to see if you’re on the way to a daily spike or a daily trough. Watching a small subset of the data change because of something you did, though, is immensely powerful. There are not many tools out there right now that let you dig deep enough to be able to understand what effects you’re having in real time. Chartbeat’s dashboard is, for all its prettiness, built around the big number; real time Google Analytics is built for watching, and not really built for publishers, though you can hack it with advanced segments to make it much more useful. If you’re lucky enough to have a tool that lets you go deep, don’t just use it to look at the big number at the top. Go for the detail. Grind fine. Experiment at small scale and document your results. And then spread out your discoveries to the rest of the newsroom. Use the numbers to change practice. Far easier said than done. This post was written with help from the folks at Help Me Write. If you want to suggest post ideas or encourage me to blog more frequently about stuff you’re interested in, I’d be massively grateful.
Elegant, pointed rant in the Onion, courtesy of CNN’s decision to put Miley Cyrus’s VMAs appearance in the top slot of their site:
There was nothing, and I mean nothing, about that story that related to the important news of the day, the chronicling of significant human events, or the idea that journalism itself can be a force for positive change in the world. For Christ’s sake, there was an accompanying story with the headline “Miley’s Shocking Moves.” In fact, putting that story front and center was actually doing, if anything, a disservice to the public. And come to think of it, probably a disservice to the hundreds of thousands of people dying in Syria, those suffering from the current unrest in Egypt, or, hell, even people who just wanted to read about the 50th anniversary of Martin Luther King’s “I Have A Dream” speech.
But boy oh boy did it get us some web traffic.
The argument’s not one that purely applies to online news (see also: recent Sun front page, every Daily Express splash for quite some time). Appealing to a mass audience is one way of trying to keep generalist news organisations in business so they can also do the harder, less grabby, more worthy news – selling sweets to fund the broccoli business. There’s a strong argument too that people are interested in many things: I can care about Syria and Cyrus simultaneously, and if someone who comes for the twerking can be persuaded to stick around for the complex international news coverage then that can be a valid growth tactic for generalist outlets. But that doesn’t mean it’ll happen organically, without a strategy to convert the Miley fans into long-term readers. And it doesn’t mean that giving the two stories equivalent billing is wise, unless you’re making a Mail-style move towards a very specific editorial tone.
You don’t have to stop doing the fun stuff, the cheeky and irreverent things, the entertainment journalism, in order to be a serious news outlet – but packaging and context do still matter online. People who go to your front page – your most loyal readers – notice shifts in your editorial approach to these sorts of stories, and will judge you on these things. It’s a deliberate, conscious editorial decision to put twerking in the top slot or rosy cheeks on the front page. There’s definite sense in promoting what your readers most want to read, and in using data to guide editorial strategy. But the key word in that sentence is guide, not subvert or overrule. It’s not the traffic play the Onion’s really angry about – it’s the editorial strategy that underlies it.
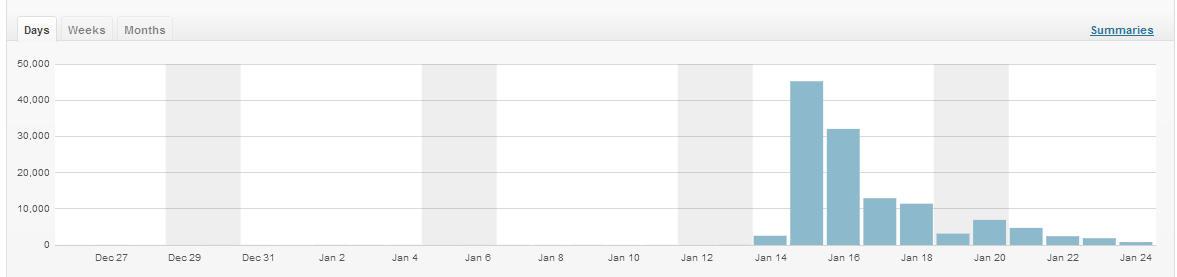
Next day it hit 45,000 views, and broke our web hosting. Over 72 hours it got more than 100,000 views, garnered 120 comments, was syndicated on Gizmodo and brought Grant about 400 more followers on Twitter. Here’s what I learned.
1. Site speed matters
The biggest limit we faced during the real spike was CPU usage. We’re on Evohosting, which uses shared servers and allots a certain amount of usage per account. With about 180-210 concurrent visitors and 60-70 page views a minute, according to Google Analytics real-time stats, the site had slowed to a crawl and was taking about 20 seconds to respond.
WordPress is a great CMS, but it’s resource-heavy. Aside from single-serving static HTML sites, I was running Look Robot, this blog, Zombie LARP, and, when I checked, five other WordPress installations that were either test sites or dormant projects from the past and/or future. Some of them had caching on, some didn’t; Grant’s blog was one of the ones that didn’t.
So I fixed that. Excruciatingly slowly, of course, because everything took at least 20 seconds to load. Deleting five WordPress sites, deactivating about 15 or 20 non-essential plugins, and installing WP Super Cache sped things up to a load time between 7 and 10 seconds – still not ideal, but much better. The number of concurrent visitors on site jumped up to 350-400, at 120-140 page views a minute – no new incoming links, just more people bothering to wait until the site finished loading.
2. Do your site maintenance before the massive traffic spike happens, not during
Should be obvious, really.
3. Things go viral in lots of places at once
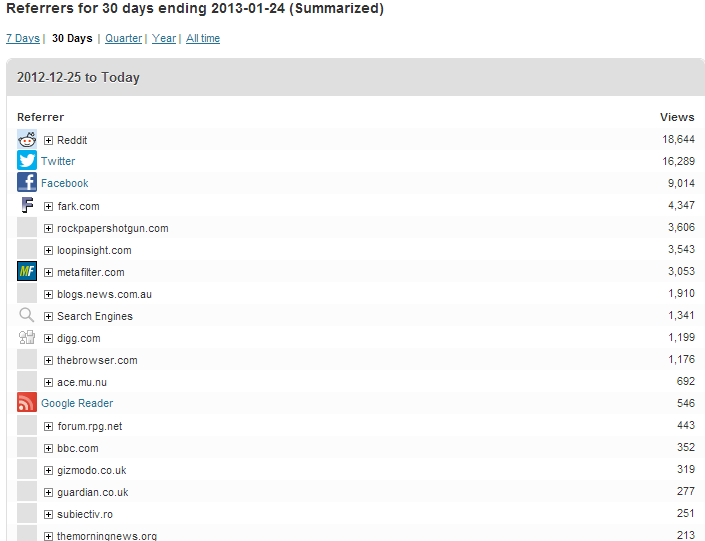
Grant’s post started out on Twitter, but spread pretty quickly to Facebook off the back of people’s tweets. From there it went to Hacker News (where it didn’t do well), then Metafilter (where it did), then Reddit, then Fark, at the same time as sprouting lots of smaller referrers, mostly tech aggregators and forums. The big spike of traffic hit when it was doing well from Metafilter, Fark and Reddit simultaneously. Interestingly, the Fark spike seemed to have the longest half-life, with Metafilter traffic dropping off more quickly and Reddit more quickly still.
4. It’s easy to focus on activity you can see, and miss activity you can’t
Initially we were watching Twitter pretty closely, because we could see Grant’s tweet going viral. Being able to leave a tab open with a live search for a link meant we could watch the spread from person to person. Tweeters with large follower counts tended to be more likely to repost the link rather than retweeting, and often did so without attribution, making it hard to work out how and where they’d come across it. But it was possible to track back individual tweets based on the referrer string, thanks to the t.co URL wrapper. From some quick and dirty maths, it looks to me like the more followers you have, the smaller the click-through rate on your tweets – but the greater the likelihood of retweets, for obvious reasons.
Around midday, Facebook overtook Twitter as a direct referrer. We’d not been looking at Facebook at all. Compared to Twitter and Reddit, Facebook is a bit of a black box when it comes to analytics. Tonnes of traffic is coming, but who from? I still haven’t been able to find out.
5. The more popular an article is, the higher the bounce rate
This doesn’t *always* hold true. However, I can’t personally think of a time when I’ve witnessed it being falsified. Reddit in particular is also a very high bounce referrer, due to its nature, and news as a category tends to see very high bounce especially from article pages, but it does seem to hold true that the more popular something is the more likely people are to leave without reading further. Look, Robot’s bounce rate went from about 58% across the site to 94% overall in 24 hours.
My feeling is that this is down to the ways people come across links. Directed searching for information is one way: that’s fairly high-bounce, because a reader hits your site and either finds what they’re looking for or doesn’t. Second clicks are tricky to get. Then there’s social traffic, where a click tends to come in the form of a diversion from an existing path: people are reading Twitter, or Facebook, or Metafilter, they click to see what people are talking about, then they go straight back to what they were doing. Getting people to break that path and browse your site instead – distracting them, in effect – is a very, very difficult thing to do.
The head of a rather long tail.
6. Fark leaves a shadow
Fark’s an odd one – not a site that features frequently in roundups of traffic drivers, but it can still be a big referrer to unusual, funny or plain daft content. It works like a sort of edited Reddit – registered users submit links, and editors decide what goes on the front page. Paying subscribers to the site can see everything that’s submitted, not just the edited front. I realised before it happened that Grant was about to get a link from their Geek front, when the referrer total.fark.com/greenlit started to show up in incoming traffic – that URL, behind a paywall, is the place where links that have been OKed are queued to go on the fronts.
7. The front page of Digg is a sparsely populated place these days
I know that Grant’s post sat on the front page of Digg for at least eight hours. In total, it got just over 1,000 referrals. By contrast, the post didn’t make it to the front page of Reddit, but racked up more than 20,000 hits mostly from r/technology.
8. Forums are everywhere
I am always astonished at the vast plethora of niche-interest forums on the internet, and the amount of traffic they get. Much like email, they’re not particularly sexy – no one is going to write excitable screeds about how forums are the next Twitter or how exciting phpBB technology is – but millions of people use them every day. They’re not often classified as ‘social’ referrers by analytics tools, despite their nature, because identifying what’s a forum and what’s not is a pretty tricky task. But they’re everywhere, and while most only have a few users, in aggregate they work to drive a surprising amount of traffic.
Grant’s post got picked up on forums on Bad Science, RPG.net, Something Awful, the Motley Fool, a Habbo forum, Quarter to Three, XKCD and a double handful of more obscure and fascinating places. As with most long tail phenomena, each one individually isn’t a huge referrer, but the collection gets to be surprisingly big.
9. Timing is everything…
It’s hard to say what would have happened if that piece had gone up this week instead, but I don’t think it would have had the traffic it has. Grant’s post hit a chord – the ludicrous nature of tech events – and tapped into post-CES ennui and the utter daftness that was the Qualcomm keynote this year.
10. …but anything can go viral
Last year I was on a games journalism panel at the Guardian, and I suggested that it was a good idea for aspiring journalists to write on their own sites as though they were already writing for the people they wanted to be their audience. I said something along the lines of: you never know who’s going to pick it up. You never know how far something you put online is going to travel. You never know: one thing you write might take off and put you under the noses of the people you want to give you a job. It’s terrifying, because anything you write could explode – and it’s hugely exciting, too.
The sample size is 28 pieces of content across 7 news stories – that content includes liveblogs, articles, picture galleries. That’s a startlingly small number for a sample which is meant to be representative.
The study does not look at how these stories were promoted, or whether they were running stories (suited to live coverage), reaction blogs, or other things.
The traffic sample is limited to news stories, and does not include sports, entertainment or other areas where liveblogs may be used, and that may have different traffic profiles.
The study compares liveblogs, which often take a significant amount of time and editorial resource, with individual articles and picture galleries, some of which may take much less time and resource. If a writer can create four articles in the time it takes to create a liveblog, then the better comparison is between a liveblog and the equivalent amount of individual, stand-alone pieces.
The study is limited to the Guardian. There’s no way to compare the numbers with other publications that might treat their live coverage differently, so no way to draw conclusions on how much of the traffic is due to the way the Guardian specifically handles liveblogs.
The 300% figure refers to pageviews. Leaving aside the fact that this is not necessarily the best metric for editorial success, the Guardian’s liveblogs autorefresh, inflating the pageview figure for liveblogs.
All that shouldn’t diminish the study’s other findings, and of course it doesn’t mean that the headline figure is necessarily wrong. But I would take it with a hefty pinch of salt.