At the recent ONA conference, Liz Heron, who oversees Facebook’s news partnerships, came in for some questioning about how news organisations can do well on the platform – something that’s a cause of some consternation for many, as it becomes increasingly clear how important it is as a mass distribution service. This is one of her responses:
To do well on Facebook, just create good content says Liz Heron #ona14
This is a familiar line from Facebook – I’ve been on panels with other employes who’ve said exactly the same thing. But while I have the greatest respect for Heron and understand that she has to present Facebook’s best side in public – and that a tweet may be cutting context away from a larger argument – this statement is demonstrably false. Even skimming the rather fraught question of what exactly “good” means in this context, it’s questionable whether quizzes and lists such as those that have brought Playbuzz its current success are in any meaningful way replicable for most news organisations.
It’s not that Playbuzz is “gaming the algorithm” necessarily, though it may be. It’s that the algorithm is not designed to promote news content. Facebook’s recent efforts to change that are, quite literally, an admission of that fact. Facebook itself knows that good – as in newsworthy, important, relevant, breaking, impactful, timely – is not sufficient for success on its platform; it sees that as a problem, now, and is moving to fix it.
In the mean time, creating “good” content will certainly help, but it won’t be sufficient. You can bypass that process completely by getting your community to create mediocre content that directly taps into questions of identity, like Playbuzz’s personality quizzes, and giving every piece absolutely superbly optimised headlines and sharing tools. You can cheerfully bury excellent work by putting it under headlines that don’t explain what on earth the story’s about, or are too long to parse, or are simply on subjects that people will happily read for hours but don’t want to associate themselves with publicly.
Time and attention are under huge pressure online. Facebook are split testing everything you create against everything else someone might want to see, from family photos to random links posted by people they’ve not met since high school, and first impressions matter enormously. “Good” isn’t enough for the algorithm, or for people who come to your site via their Facebook news feed. It never has been. Facebook should stop pretending that it is.
“If people click on an article and spend time reading it, it suggests they clicked through to something valuable. If they click through to a link and then come straight back to Facebook, it suggests that they didn’t find something that they wanted. With this update we will start taking into account whether people tend to spend time away from Facebook after clicking a link, or whether they tend to come straight back to News Feed when we rank stories with links in them.”
This is an update aimed squarely at the curiosity gap, designed to take out clickbait (whatever that means). It isn’t going to touch Buzzfeed’s lists, for example, because their informational heads give you exactly as much knowledge as you need to decide whether to click, and they’re geared around getting you to scroll all the way to the end. It won’t hurt any sites successfully getting second clicks from Facebook traffic, rare as those are. It might hurt Upworthy and its imitators, but not much, because of the method Facebook’s using to decide what’s valuable and what’s not. Tracking time on page is going to hurt thin, spammy sites where a user’s first response is to click back; Upworthy is very focussed on dwell time as part of its core engagement metric, and it’s certainly neither thin nor spammy.
But one unintended consequence of a focus on time away from the Facebook feed is a negative impact on breaking news. Facebook’s algorithm already struggles with news because of its lack of timeliness and the slow way it propagates through newsfeeds; it’s fine for features, for comment, for heartwarming kitten videos, and all sorts of other less-timely reads, but if you’re seeing a 12-hour-old news post there’s every chance it’s no longer really news. Recent events in Ferguson have highlighted Facebook’s ongoing problems in this area, and this risks adding another issue: news is fast, and Facebook is prioritising slow.
Time on site isn’t a particularly sensible metric to use for news: most people hunting for news want it quickly, and then they want to get on with the rest of their lives. The inverted pyramid of news writing is built around that principle – give the reader all they need as quickly as possible, then build in detail later for those who want it.
Increasingly, news sites are using stub articles – a few sentences or shorter – to break fast-moving stories, atomising them into smaller and smaller pieces. Those pieces might take seconds to read. If they’re promoted on Facebook, how does a news reader clicking through, reading the whole thing then backing out look different from someone clicking on a curiosity-gap headline then backing out because it wasn’t what they wanted?
One of the fundamental problems with a few large companies controlling the primary means of mass digital distribution is that media organisations who want to be widely read have to change their work to fit those distribution channels. Not just in terms of censorship – no naked female nipples in your Facebook images, no beheading videos on Twitter – but less obviously, and more integrally, in terms of form.
Online media has as many formal constraints as print, perhaps more, if you want to be widely read; they’re just trickier, more self-contradictory, and constantly shifting. Facebook’s changes are going to have an effect on what news looks like, just as Google’s algorithm did (and still does – Google News requires posts to have a minimum of 50 words in order to count as “news”, which is still shaping decisions about how to break what where in newsrooms).
If Facebook thinks fast, informative, snippets are less important in its newsfeed than longer reads, then news is either going to keep losing out – or change its shape to accommodate the algorithm.
In news-that-ought-to-be-satire-but-isn’t, the AV Club reports, via New Scientist, that Facebook has been manipulating users’ feeds in order to test whether they can manipulate their emotions. 689,003 users, to be precise.
The full paper is here, and makes for interesting reading. The researchers found that, yes, emotional states are contagious across networks, even if you’re only seeing someone typing something and not interacting with them face-to-face. They also found that people who don’t see emotional words are less expressive – a “withdrawal effect”.
Where things get rather concerning is the part where Facebook didn’t bother telling any of its test subjects that they were being tested. The US has a few regulations governing clinical research that make clear informed consent must be given by human test subjects. Informed consent requires subjects to know that research is occurring, be given a description of the risks involved, and have the option to refuse to participate without being penalised. None of these things were available to the anonymous people involved in the study.
As it happens, I have to use Facebook for work. I also happen to have a chronic depressive disorder.
It would be interesting to know whether Facebook picked me for their experiment. It’d certainly be interesting to know whether they screened for mental health issues, and how they justified the lack of informed consent about the risks involved, given they had no way to screen out those with psychiatric and psychological disorders that might be exacerbated by emotional manipulations, however tangential or small.
The researchers chose to manipulate the news feed in order to remove or amplify emotional content, rather than by observing the effect of that content after the fact. There’s an argument here that Facebook manipulates the news feed all the time anyway, therefore this is justifiable – but unless Facebook is routinely A/B testing on its users’ happiness and emotional wellbeing, the two things are not equivalent. Testing where you click is different to testing what you feel. A 0.02% increase in video watch rates is not the same as a 0.02% increase in emotionally negative statements. One of these things has the potential for harm.
The effect the researchers found, in the end, was very small. That goes some way towards explaining their huge sample size: the actual contagion effect of negativity or positivity on any one individual is so tiny that it’s statistically significant only across a massive pool of people.
But we know that only because they did the research. What if the effect had been larger? What if the effect on the general population was small, but individuals with certain characteristics – perhaps, say, those with chronic depressive disorders – experienced much larger effects? At what point would the researchers have decided it would be a good idea to tell people, after the fact, that they had been deliberately harmed?
Facebook is taking reach away from brand pages. That much seems pretty obvious from the growing anger of people who’ve spent time and energy building audiences on Facebook, only to find they now can only reach a small proportion of them without paying. Mathew Ingram has a great piece today on GigaOm looking at this in a lot more detail, covering the negative reactions by both major brands and individuals looking to use Facebook to promote their work.
In any case, every successive change or tweak of its algorithms by Facebook — not to mention its penchant for removing content for a variety of reasons, something Twitter only does when there is a court order — reinforces the idea that the company is not running the kind of social network many people assumed it was. In other words, it is not an open platform in which content spreads according to its own whims: like a newspaper, Facebook controls what you see and when.
At the same time as all this is going on, Facebook is giving a pleasant boost to pages belonging to news organisations; the Guardian isn’t the only news organisation seeing a rapid rise in the numbers of page likes it’s receiving, starting on March 18. That’s driven by Page Suggestions, a relatively recent feature that, well, suggests pages to users, generally based on posts they’ve liked or interacted with, though it’s possible Facebook’s changing/has changed the situations when it displays that feature.
It certainly seems like an algorithm tweak that’s designed to benefit news pages by boosting their audience, but not necessarily their reach – while news pages are certainly getting more exposure, that’s no guarantee the posts themselves are reaching more people. It could be a mask; boosting audience numbers for particular types of pages in order to counteract a general lowering of reach, so that news brands end up more or less where they started in terms of the people who actually see their Facebook shares. Or it could be a rebalancing, promoting news pages at the expense of other brands on the basis that Facebook would much rather you got news in your news feed than advertising.
Or, given the lack of transparency of Facebook’s approach across the board, it could of course be a blip; an unintended consequence of downgrading some types of content that leaves news at an advantage, for now. Either way, it’s not likely to last unless it helps Facebook become the sort of Facebook that it thinks it wants to be – and it’s another reminder, even on the up side, that this isn’t a platform that can be controlled.
At the launch of BuzzFeed Australia on Friday, Scott Lamb gave an interesting keynote aimed at puncturing some commonly-held myths about the internet and social sharing. It was a good speech, well written up here, but at one point he gave a view that social is essentially an evolution of the net. His idea – at least as I understood it – was that the internet had gone from portals, through search, and was now at social; that search is something of the past.
Perhaps it’s not possible to say this clearly enough. Search and social as they’re currently used are two sides of the same coin – two strategies for discovering information that serve two very different purposes. Search is where you go to find information you already know exists; social is where you go to be surprised with something you didn’t know you wanted. If you know something’s happened very recently, these days, you might go to Twitter rather than Google, but once you’re there, you search. And if a clever headline crafted for Twitter doesn’t contain the keywords someone’s going to search for, then it’s going to be as impossible to find it on Twitter as it is in Google. It’s easy to forget that a hashtag is just a link to a Twitter search.
But Twitter isn’t what we’re really talking about here. “Social” when it comes to traffic, at the moment, is a code word that means Facebook – in much the same way that “social” for news journalists is a code word that means Twitter. And optimising headlines exclusively for Facebook gives you about as much leeway to be creative and clever as optimising exclusively for Google. You can do whatever you want as long as you follow the rules for what works, and those rules are surprisingly restrictive.
Lamb, to give him credit, pointed out the problem with the current over-reliance on Facebook: they burn their partners, they have full control over their feeds and what appears in them, and they have shown no hesitation in the past in shifting traffic away from publishers if it serves them or their users. All the same problems as a lot of sites have with Google.
David Higgerson has an interesting post that feeds into this issue, asking whether the growth of social and mobile has “saved the clever headline”. He writes that instead of straight keyword optimisation, social headlines require a reaction from the reader, and says:
This should be great news for publishers steeped in writing great headlines. Just as having a website isn’t quite like having multiple editions throughout the day, the need to force a smile or an emotion in a headline doesn’t mean the days of punderful headlines can return, but there are similarities we can draw on.
Lamb also said that optimising for search is all about optimising for machines, while social is all about optimising for people. Like Higgerson, he expressed a hope that social headlines mean a more creative approach – and the idea that now we’re moving past the machine-led algorithms news can be more human.
But search, like social is people; social, like search, is machines. Online we are all people mediated by machines, and we find content through algorithms that drive our news feeds and search results. Optimising purely for Facebook’s algorithm produces different results to optimising purely for Google’s, but it’s no less risky a strategy – and no more or less human.
Steve Buttry has a great response to a reporter worried about being scooped by the competition if they post on Twitter. He argues that: “You can’t get scooped because competition gets tipped to a story when you tweet about it. Your tweets already scooped the competition.”
That’s true, but not quite complete. You may have scooped the competition, but you’ve only scooped them on Twitter – for readers who don’t use Twitter or who don’t follow you there, you might not have broken any news at all. The choice of where to break stories or how to develop them live isn’t just “Twitter and/or your own website”. Twitter matters, that’s certain, but what’s less cut and dried is whether it matters more than anywhere else, for you and for your readers.
Sometimes being first on Twitter is worth a huge amount of prestige and traffic for your work. Sometimes, in all honesty, it’s just nice-to-have – the traffic and prestige you really want is elsewhere. Would you rather be first to tweet, or would you rather be the first thing people see in their Facebook newsfeed or the first with a chance at a link from r/worldnews? Is the audience for what you’re writing actually using Twitter, or are they elsewhere? Are you better off dashing off an alert to your mobile app users, or an email to a specialised list, before you take to Twitter?
All Buttry’s advice for how to report live, digitally and socially, is excellent. And it all also has platform-agnostic applications. You can post to a brand Facebook page as well as – or instead of – a brand Twitter account; at the moment, with all the dials turned up, that’s likely to have a significant effect.
You can argue the Facebook audience will most likely disappear when Facebook makes another newsfeed tweak; that ignores the fact that right now is a good time to put your work in front of people who might never have seen it before and might never see it again unless you go where they are and show them.
It also misses the important point here, which is that no one platform is the answer in all situations for every news organisation all of the time. You have to build a strategy that will be flexible enough to respond when something changes, positively or negatively, on a social platform. Social and search sites do not owe you traffic, and relying on one at the expense of others is not sensible in the long term. You have to be willing to allocate resources away from the shiny media-friendly very-visible things and towards the more oblique, less obvious, less sexy things. You have to be able to go where your audience is, not just where you are as a journalist. If your audience is all hanging out on an obscure forum, go post there.
That doesn’t mean you shouldn’t or can’t also try to be first on Twitter – if you’re doing news seriously, you absolutely should. Twitter’s huge, and hugely important, but it isn’t all there is to social news, and it’s crucial to think about where else your readers might be. If you’re only thinking about breaking news on Twitter, you’re not thinking broadly enough yet. Break news in weird places, if that’s where your audience is.
There’s a lot of chatter around about Facebook at the moment in the light of the high levels of traffic it’s driving to publishers, and the way it’s trying to define itself as a news destination as well as a social one. Particularly interesting post on this topic at AllThings D today, which talks about the not-entirely-successful news feed redesign, and the dichotomy between what Facebook seems to want for itself and what its users seem to want from it.
Most people think of Facebook in a similar way: It’s a place to share photos of your kids. It’s a way to keep up with friends and family members. It’s a place to share a funny, viral story or LOLcat picture you’ve stumbled upon on the Web.
This is not how Facebook thinks of Facebook. In Mark Zuckerberg’s mind, Facebook should be “the best personalized newspaper in the world.” He wants a design-and-content mix that plays up a wide array of “high-quality” stories and photos.
The gap between these two Facebooks — the one its managers want to see, and the one its users like using today — is starting to become visible.
I’m not a fan of the constant return to the print metaphor whenever we talk about new ways of depicting news online – the newspaper idea – because it tends so badly to limit the scope of what’s possible to what’s already been done. It’s an appeal to authority, the old authority of print pages, the idea not just of a curated experience delivered as a package but also a powerful force in the political world. An authoritative voice. And it’s likely that Facebook would not be upset if, as a side effect of becoming a more newspaper-ish experience, it also gained more power.
But what we’re talking about here isn’t just a newspaper-Facebook vs a not-a-newspaper-Facebook. It’s the tension between tabloid and broadsheet style, played out in microcosm in the news feed, just as it’s being played out in a lot of news organisations that used to be newspapers. It’s the question of whether you can really wield power and authority, whether you can be trusted, if you’re posting hard news alongside cat gifs. It’s the Buzzfeed questions played out without any content to publish, an editor’s dilemma without editorial control.
It’s also an identity question, because it always is with social media. We’re not one person universally across all our services; we don’t behave the same way on Twitter as we do on Facebook. What Zuckerberg wants isn’t just a news feed change, it’s also a shift in the way we express and construct our Facebook selves – a shift more towards the Twitter self, perhaps. A more serious, more worthy consumption experience and sharing motive, a more informational and less conversational self.
Maybe that’s a really difficult problem to solve, adjusting the way identity works within an online service. Or maybe tweaking people is easy to do, if you just find the right algorithm and design tweaks.
Some years ago, the tech industry set out to redefine our perception of the web. Facebook (and other similar sites) grew at amazing rates and their reasonable focus on the “social network” and the “social graph”, made “social networks” the new kid on the block.
But even though the connections of each individual user are his social network, these sites are not social networks. They are social networking places.
This is an important distinction. They are places, not networks. Much like your office, school, university, the place where you usually spend your summer vacation, the pub where your buddies hang out or your hometown.
And, much like your office, school, university, etc, they all have their own behavioural expectations and norms. When those spaces get big and full of people jostling for room, if they aren’t broken up into their own smaller spaces – or if the partitions are porous – those differing expectations rub up against each other in all sorts of interesting and problematic ways.
The Twitter I have is not the Twitter you have, because we follow different folks and interact with them in our own ways. There are pretty regular examples of this disparity: when people write posts about how Twitter’s changed, it’s no fun any more, but the reality is that it’s just the folks they follow and talk to that have changed how they use it. My Twitter experience doesn’t reflect that – I’m in a different space with different people.
Part of the abuse problem all online spaces face is working out their own norms of behaviour and how to deal with incidents that contravene them. One of the particular problems faced by Twitter and a few others is how to deal with incidents that turn up because of many different, overlapping, interconnected spaces and the different expectations of each one.
And on practical ways to handle those problems, go read this excellent post by an experienced moderator. It’s too good to quote chunks here.
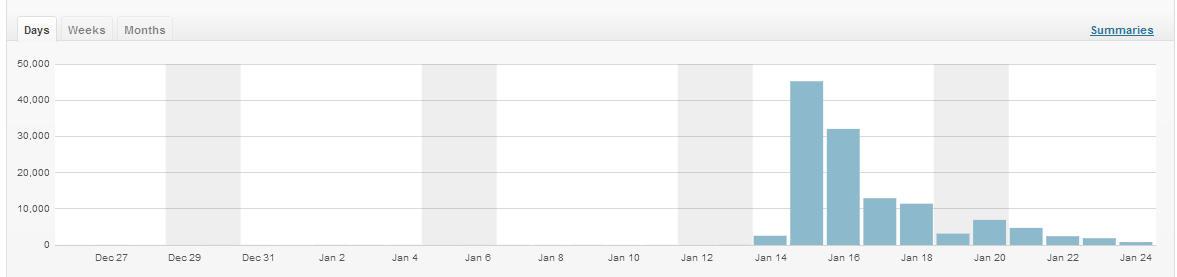
Next day it hit 45,000 views, and broke our web hosting. Over 72 hours it got more than 100,000 views, garnered 120 comments, was syndicated on Gizmodo and brought Grant about 400 more followers on Twitter. Here’s what I learned.
1. Site speed matters
The biggest limit we faced during the real spike was CPU usage. We’re on Evohosting, which uses shared servers and allots a certain amount of usage per account. With about 180-210 concurrent visitors and 60-70 page views a minute, according to Google Analytics real-time stats, the site had slowed to a crawl and was taking about 20 seconds to respond.
WordPress is a great CMS, but it’s resource-heavy. Aside from single-serving static HTML sites, I was running Look Robot, this blog, Zombie LARP, and, when I checked, five other WordPress installations that were either test sites or dormant projects from the past and/or future. Some of them had caching on, some didn’t; Grant’s blog was one of the ones that didn’t.
So I fixed that. Excruciatingly slowly, of course, because everything took at least 20 seconds to load. Deleting five WordPress sites, deactivating about 15 or 20 non-essential plugins, and installing WP Super Cache sped things up to a load time between 7 and 10 seconds – still not ideal, but much better. The number of concurrent visitors on site jumped up to 350-400, at 120-140 page views a minute – no new incoming links, just more people bothering to wait until the site finished loading.
2. Do your site maintenance before the massive traffic spike happens, not during
Should be obvious, really.
3. Things go viral in lots of places at once
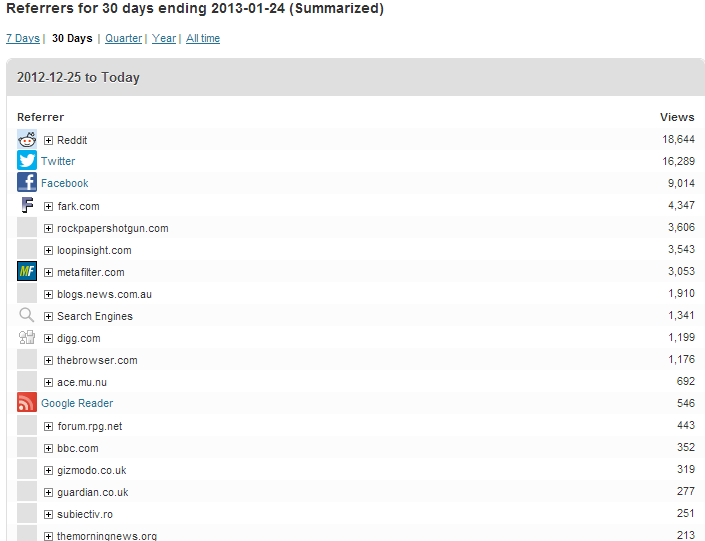
Grant’s post started out on Twitter, but spread pretty quickly to Facebook off the back of people’s tweets. From there it went to Hacker News (where it didn’t do well), then Metafilter (where it did), then Reddit, then Fark, at the same time as sprouting lots of smaller referrers, mostly tech aggregators and forums. The big spike of traffic hit when it was doing well from Metafilter, Fark and Reddit simultaneously. Interestingly, the Fark spike seemed to have the longest half-life, with Metafilter traffic dropping off more quickly and Reddit more quickly still.
4. It’s easy to focus on activity you can see, and miss activity you can’t
Initially we were watching Twitter pretty closely, because we could see Grant’s tweet going viral. Being able to leave a tab open with a live search for a link meant we could watch the spread from person to person. Tweeters with large follower counts tended to be more likely to repost the link rather than retweeting, and often did so without attribution, making it hard to work out how and where they’d come across it. But it was possible to track back individual tweets based on the referrer string, thanks to the t.co URL wrapper. From some quick and dirty maths, it looks to me like the more followers you have, the smaller the click-through rate on your tweets – but the greater the likelihood of retweets, for obvious reasons.
Around midday, Facebook overtook Twitter as a direct referrer. We’d not been looking at Facebook at all. Compared to Twitter and Reddit, Facebook is a bit of a black box when it comes to analytics. Tonnes of traffic is coming, but who from? I still haven’t been able to find out.
5. The more popular an article is, the higher the bounce rate
This doesn’t *always* hold true. However, I can’t personally think of a time when I’ve witnessed it being falsified. Reddit in particular is also a very high bounce referrer, due to its nature, and news as a category tends to see very high bounce especially from article pages, but it does seem to hold true that the more popular something is the more likely people are to leave without reading further. Look, Robot’s bounce rate went from about 58% across the site to 94% overall in 24 hours.
My feeling is that this is down to the ways people come across links. Directed searching for information is one way: that’s fairly high-bounce, because a reader hits your site and either finds what they’re looking for or doesn’t. Second clicks are tricky to get. Then there’s social traffic, where a click tends to come in the form of a diversion from an existing path: people are reading Twitter, or Facebook, or Metafilter, they click to see what people are talking about, then they go straight back to what they were doing. Getting people to break that path and browse your site instead – distracting them, in effect – is a very, very difficult thing to do.
The head of a rather long tail.
6. Fark leaves a shadow
Fark’s an odd one – not a site that features frequently in roundups of traffic drivers, but it can still be a big referrer to unusual, funny or plain daft content. It works like a sort of edited Reddit – registered users submit links, and editors decide what goes on the front page. Paying subscribers to the site can see everything that’s submitted, not just the edited front. I realised before it happened that Grant was about to get a link from their Geek front, when the referrer total.fark.com/greenlit started to show up in incoming traffic – that URL, behind a paywall, is the place where links that have been OKed are queued to go on the fronts.
7. The front page of Digg is a sparsely populated place these days
I know that Grant’s post sat on the front page of Digg for at least eight hours. In total, it got just over 1,000 referrals. By contrast, the post didn’t make it to the front page of Reddit, but racked up more than 20,000 hits mostly from r/technology.
8. Forums are everywhere
I am always astonished at the vast plethora of niche-interest forums on the internet, and the amount of traffic they get. Much like email, they’re not particularly sexy – no one is going to write excitable screeds about how forums are the next Twitter or how exciting phpBB technology is – but millions of people use them every day. They’re not often classified as ‘social’ referrers by analytics tools, despite their nature, because identifying what’s a forum and what’s not is a pretty tricky task. But they’re everywhere, and while most only have a few users, in aggregate they work to drive a surprising amount of traffic.
Grant’s post got picked up on forums on Bad Science, RPG.net, Something Awful, the Motley Fool, a Habbo forum, Quarter to Three, XKCD and a double handful of more obscure and fascinating places. As with most long tail phenomena, each one individually isn’t a huge referrer, but the collection gets to be surprisingly big.
9. Timing is everything…
It’s hard to say what would have happened if that piece had gone up this week instead, but I don’t think it would have had the traffic it has. Grant’s post hit a chord – the ludicrous nature of tech events – and tapped into post-CES ennui and the utter daftness that was the Qualcomm keynote this year.
10. …but anything can go viral
Last year I was on a games journalism panel at the Guardian, and I suggested that it was a good idea for aspiring journalists to write on their own sites as though they were already writing for the people they wanted to be their audience. I said something along the lines of: you never know who’s going to pick it up. You never know how far something you put online is going to travel. You never know: one thing you write might take off and put you under the noses of the people you want to give you a job. It’s terrifying, because anything you write could explode – and it’s hugely exciting, too.
This is brilliant. Identity online is multifaceted, and the explosion in popularity of Instagram and Pinterest is in part about performing single facets of identity, mythologising ourselves through imagery.
Instead of thinking of social media as a clear window into the selves and lives of its users, perhaps we should view the Web as being more like a painting.
This is why Facebook’s desire to own our identities online is fundamentally flawed; our Facebook identities are not who we are, and they are too large and cumbersome and singular to represent us all the time. Google+ has the same problem, of course. Frictionless sharing introduces an uncomfortable authenticity – Facebook identities thus far have been carefully and deliberately constructed, and allowing automatically shared content to accrete into an identity is a different process, a more honest and haphazard one, that for many may spoil their work.
As we do offline, our self-presentations online are always creative, playful, and thoroughly mediated by the logic of social-media documentation.
Pinterest and Instagram are built around these playful, creative impulses to invent ourselves. Twitter remains abstract enough to encourage it too, though in textual rather than visual form. Facebook and Google identities are such large constructions that they become restrictive – you can’t experiment in the way you can with other platforms because of the weight of associations and of history – and they’re not constructed in a vacuum. They rely on interactions with friends for legitimacy – but you can’t jointly create one the way you can a Tumblr or a Pinterest board. Group identities don’t quite work. Individual identities are too heavy to play with properly. But Pinterest and Instagram and Tumblr are online scrapbooks – visual, associative, picturesque – and are just the right formats for liminal experimentation with self-construction. Creative and lightweight.